FLoC
背景
- 2020 年 1 月 Chrome 浏览器计划禁用第三方 cookies
- 2020 年 10 月发布 FLoC 白皮书
- 2021 年 1 月宣布 FLoC 计划,并宣称达到了基于 cookie 追踪方法的 95% 的效果
- 2021 年 3 月开始在 Chrome 灰度 FLoC
FLoC 简介
Federated Learning of Cohorts (FLoC) API 的目的是为了在隐私前提下能够保证进行基于兴趣的广告推送。这个 API 依赖于一种基于浏览历史的簇分配算法来得到一个簇 id,同时 Chrome 会保证这个 id 至少有 k 个不同的用户,即满足k 匿名要求。
在设计方案的时候,Google 参考了以下几个原则:
- 簇 id 可以避免对个人跨网站的追踪
- 每一个簇能够包括有相似浏览记录的用户
- 簇分配的算法需要是无监督的
- 簇分配算法需要限制 magic numbers 的使用,即参数选择是透明的、可解释的
- 计算个人簇 id 的方法复杂度低
算法比较
白皮书中主要提出了用 SimHash 把用户的浏览历史哈希成一个 p 维的二值向量,如果用户的哈希值相同,则认为是同一个簇。同时也用其他方法来对比,主要从以下三个角度:
- 隐私性:多少比例的用户是在大的簇的?
- 功能性:在同一个簇中的用户的相似度是怎么样的?
- 中心化:簇 id 需要通过一个中心服务器来计算吗?
计算簇 id 的方法本质上是聚类的操作。
SimHash
SimHash 属于一种局部敏感哈希算法,一般用来判断文档的相似度。输入是 d 维的用户向量 x,输出一个 p 位的二值向量。
$$H_{p}(x)_{i}=0 \text { if } w_{i} \cdot x \leq 0 \text { else } 1$$其中 $w_i$ 是单位正交向量。
SimHash 其中一个重要的特征就是相似的向量更可能被哈希为相同的簇 id。两个向量被映射成相同的簇 id 的概率可以表示为
$$ Prob(H_p(x_1)=H_p(x_2)) = (1 - \frac{\theta(x_1, x_2)}{\pi})^p $$其中 $\theta(x_1, x_2)$ 是两个向量的夹角。
SimHash 的优缺点:
- 优点:计算簇 id 的时候不会用到其他用户的信息
- 缺点:不能够控制最小的簇大小,可以通过一个匿名服务器来解决,即 API 不返回不满足 k 匿名要求的簇 id。
SortingLSH
对于 SimHash 来说,选定合适的 p 是比较重要的。如果 p 过小,那么簇内部用户太多,区分度就小;如果 p 过大,那么得到的簇很有可能会违反 k 匿名的要求。
SortingLSH 可以通过对于 SimHash 聚类后处理,解决以上的问题。可以分为两步:
- 把 SimHash 得到的哈希值按照字典序排列
- 连续地生成至少 k 个哈希值的集合
同样可以证明的是,SortingLSH 在隐私保护上至少不比原版的 SimHash 实现差,因为两者都需要一个获取所有用户哈希值的中心服务器,但是它能确保每个用户都在一个符合 k 匿名条件的簇中。
Affinity hierarchical clustering
白皮书中用来做对照的一种中心聚类的方法,基于用户间相似图(相似的用户通过边来连接)来计算。主要步骤可以描述如下:
- 构建图:用户作为结点,用户向量的余弦相似度用边表示。这个过程也利用到了局部敏感哈希的方法来快速定位相似度高的用户对。
- 图聚类:利用自底向上的层次聚类方法。不断合并用户,并得到中心点。
- 类别分配:把用户类别指定为最近的中心点对应的类别。
k Random Centers
谷歌在白皮书之后提到一种局部敏感哈希的方法。方法比较简单,输入为 d 维的向量 x,哈希值 $H(x)$ 可以这么得到:
- 随机在 d 维空间取 k 个「中心点」
- $H(x)$ 即为 x 余弦距离最近的点的编码
这种方法的劣势在于簇内的相似度比之前的方案弱,同样不能保证最小的簇大小(但是可以观察到由于是随机取的中心点,簇的大小分布比较均匀)。
数据集验证
谷歌在两类数据集上做了验证:
- 公共数据集,主要是 MSD 歌曲数据集和 MovieLens 电影数据集。
- 谷歌广告展示数据集。
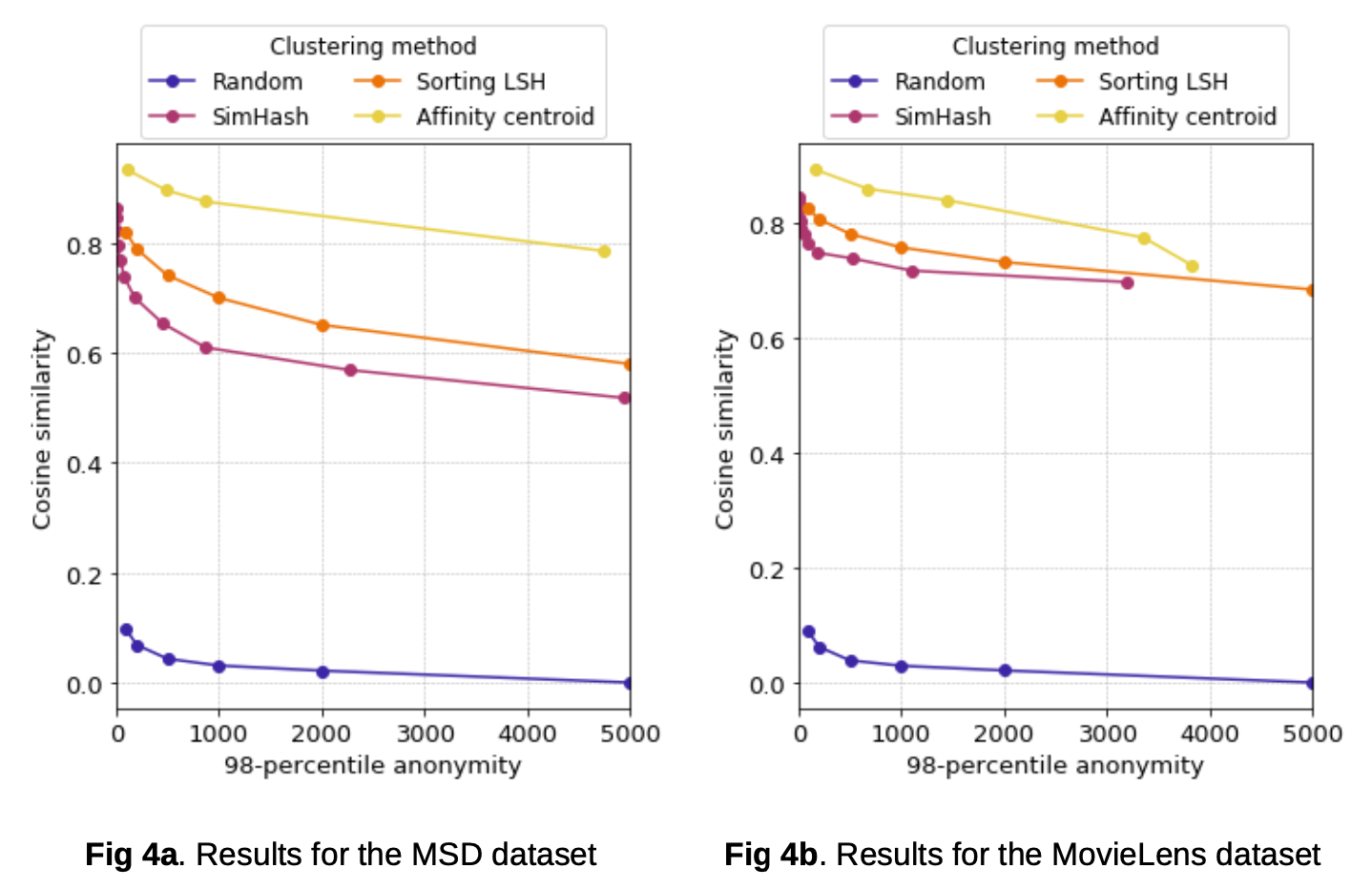
不同的数据集特征提取和衡量指标会有差别。对于 MSD 的特征提取可以参考下图:

对此的评价指标主要是围绕簇内部的异常情况,即聚类性能度量中的一种内部指标。计算一个聚类中所有用户(包括中心点)之间的平均余弦相似度,即簇间相似度。结果显示 SimHash 和 SortingLSH 大概是 AHC 的 85% 左右的效果。
在谷歌广告数据集上,特征提取的方式有所不同,因为数据集是由 URL 组成的。有几种方法来提取特征:
- 针对域名 One-hot 编码(看描述应该像是 Multi-hot,得到一个访问过的域名对应位置都为 1 的系数向量)。
- 针对域名的 TF-IDF 编码,这里主要考虑要去除比较流行的域名的影响,降低权重。
- 主题分类,把域名描述成类别(需要 API),再用各个类别的权重来描述用户(很像在公共数据集的特征提取方式)。
评估的过程也很简单,对于每一个簇中用户一周内所有涉及的网站,取 Top 10 的分类,作为兴趣数据;再取用户后一周的网站转化数据;用兴趣数据预测转化数据,计算准召。
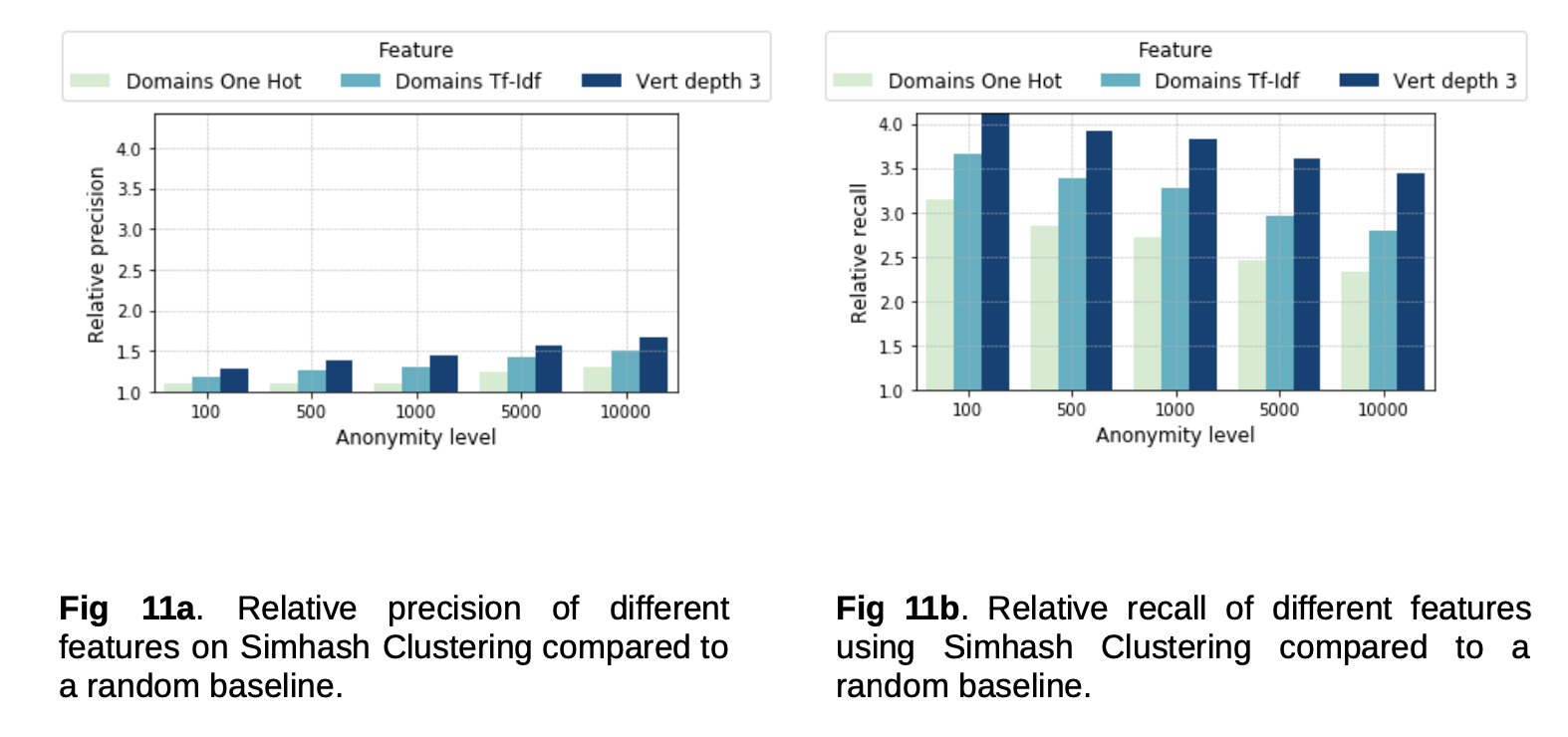
其中值得注意的是,随着匿名保护力度的提升,精准却在提升,这是因为簇越大,簇的兴趣类别更接近于热度类别。
FLoC 问答
会同时存在多个簇 id 吗?
不会。但是一个 id 可能包含多种主题的兴趣。
如果兴趣改变了,会停留在同一个簇吗?
不会。每 7 天会更新一次簇群,如果兴趣改变相应的 id 也会改变。
会和网站共享浏览历史数据吗?
不会。FLoC 是替代这样的隐私顾虑存在的,同时又能向网站暴露广告相关的信息。
会涉及敏感的类别,比如种族、宗教、性取向吗?
不会。提供簇 id 之前会分析并保证簇中的浏览历史的敏感网站比例低于一定水平。同时网站可以选择不被 FLoC 计算。参考Measuring Sensitivity of Cohorts Generated by the FLoC API。
Google Ads 会在 FLoC 有优势地位吗?
不会。Google Ads 会和其他广告平台、发布者、广告商的角色对等。FLoC 和隐私沙盒会保持开源,以供 web 社区贡献和采用。
POC 阶段实验
在推广 FLoC 之前需要做一个验证实验(Proof of Concept Experiment),主要是找到一种有效的聚类方法。
实验的算法更新在这个页面。当前版本为 chrome.2.1。
数据源
目前只有域名会被使用,而不是 URL 或者网页的内容。
限制条件
实验人群限制:
- 用户登录了谷歌账户并且同步 Chrome 历史记录
- 用户没有禁用第三方 Cookies
- 用户的谷歌活动记录和广告设置相应选项开启
域名相关限制:
- 过去 7 一天的 Chrome 历史里有已注册的域名,会导致 FLoC 的计算
- 域名的某个页面使用了 document.interestCohort() 或者被检测为广告相关会被计入
- API 被禁止或者声明了 Permissions-Policy: interest-cohort=() 的域名会被忽略
- 非公开录有的 IP 地址会被忽略
算法方案
和白皮书中介绍的有所不同,这个版本中使用的方法被称作 PrefixLSH。和 SortingLSH 比较类似。
- 浏览器会对每个域名生成一个 50 维的浮点数向量(实际用不到 50 维,大概 20 维),坐标是高斯分布的伪随机数,其中伪随机的种子通过对域名哈希生成的。
- 浏览器对所有的域名输入,生成一个 50 位的局部敏感哈希向量,即把所有输入向量求和,再按位取 sign
- Chrome 的服务端会统计 50 位的哈希向量的数量
- 开始对哈希向量进行分类,从第一位 0 或 1 开始分为两个大类,依次类推,满足每类至少 2000 个用户(实际上匿名程度大于 2000,因为不是所有用户都同步 id)。前缀即为簇 id。
- 所有的簇 id 会分发到浏览器,浏览器自己可以计算 50 位的哈希,从所有的簇 id 中找到所属的簇。
- 注意这是一种无监督的聚类方法,其中没有用到联邦学习,参数只有随机数的生成参数和最小的簇尺寸。
额外过滤
同时制订了额外过滤的方案:
- 服务端的过滤:过滤太少的簇(从算法上其实不可能成立,但是实际上随着用户行为的改变这是可能出现的情况。不能通过重新计算前缀来调整簇尺寸,因为这样会改变原有的簇 id 的含义);过滤敏感页面过多的簇。
- 浏览器端的过滤:输入少于 7 个域名;用户清除了历史记录,簇 id 会重新计算;开启了匿名模式。
实验结果
- 簇数量(过滤前):33872
- LSH 前缀大小:13 到 20 之间
- 最小簇尺寸:2000 用户
- 最小的簇内独立的域名集合数:735
- 敏感过滤簇数量:792(约 2.3%)