LLM「我是谁」之谜
前一段时间蒸馏 Claude 的话题很火。A\ 直接公开了几个厂家名单,而且有不少人拿着「你是谁?」结果回复是 Claude 截图在社媒上试图证明这一点。
虽然不可否认的是国内各家基本都在蒸,这个理由其实不太成立。尤其是今天 Opus 4.8 发布之后,用户发现在中文下面它很容易回复自己是 Qwen 或者 DeepSeek,但是英文下面不会。(https://linux.do/t/topic/2264698?tl=en)
对此我一直有个假设:这个身份认知问题其实是预训练阶段网页语料引入的,而不是显式的蒸馏导致的。因为各家数据链路其实都很成熟,不至于在后训练比较有限的数据里面没有去除这些身份标识,不然也太草台班子了。这种现象在 ChatGPT 刚出来的时候还是可以理解的。
另外我们观察到这个趋势:
- 在中文语境下面,各家外国模型有小概率会认为自己是 Qwen/DS 甚至文心一言(是你,哈基米)
- 在身份认知上,国内模型从觉得自己是 ChatGPT 逐渐变为小概率认为自己是 Claude
- 在代码语境下,更多模型会觉得自己是 Claude
一点直觉
不同产品名在互联网语料里的出现的比例和语境随着时间在变化。
ChatGPT发布最早,并且很长时间是 SOTA 和 C 端霸主,给 22 年后的互联网贡献了相当多废料(初期用户也是对它的身份认知很痴迷);Claude,尤其是 Claude Code 在最近一年逐渐在代码生成领域取得主流,而且它有一个特别的行为就是喜欢在 commit message 中注入自己的名称。DeepSeek和Qwen在中文社区中讨论度逐渐随着模型能力升高。

这里刚刚好 Qwen 系列模型开源在几个关键时间点中间,可以用 Base 模型不同语境下的生成概率来直接分析这个语料对模型的影响。SFT/RL 模型做了一定程度的身份认知修正,每家重视程度不同,用 Base 模型是比较直接的方法。当然最直接的就是分析语料了,但是我们拿不到。
实验设计
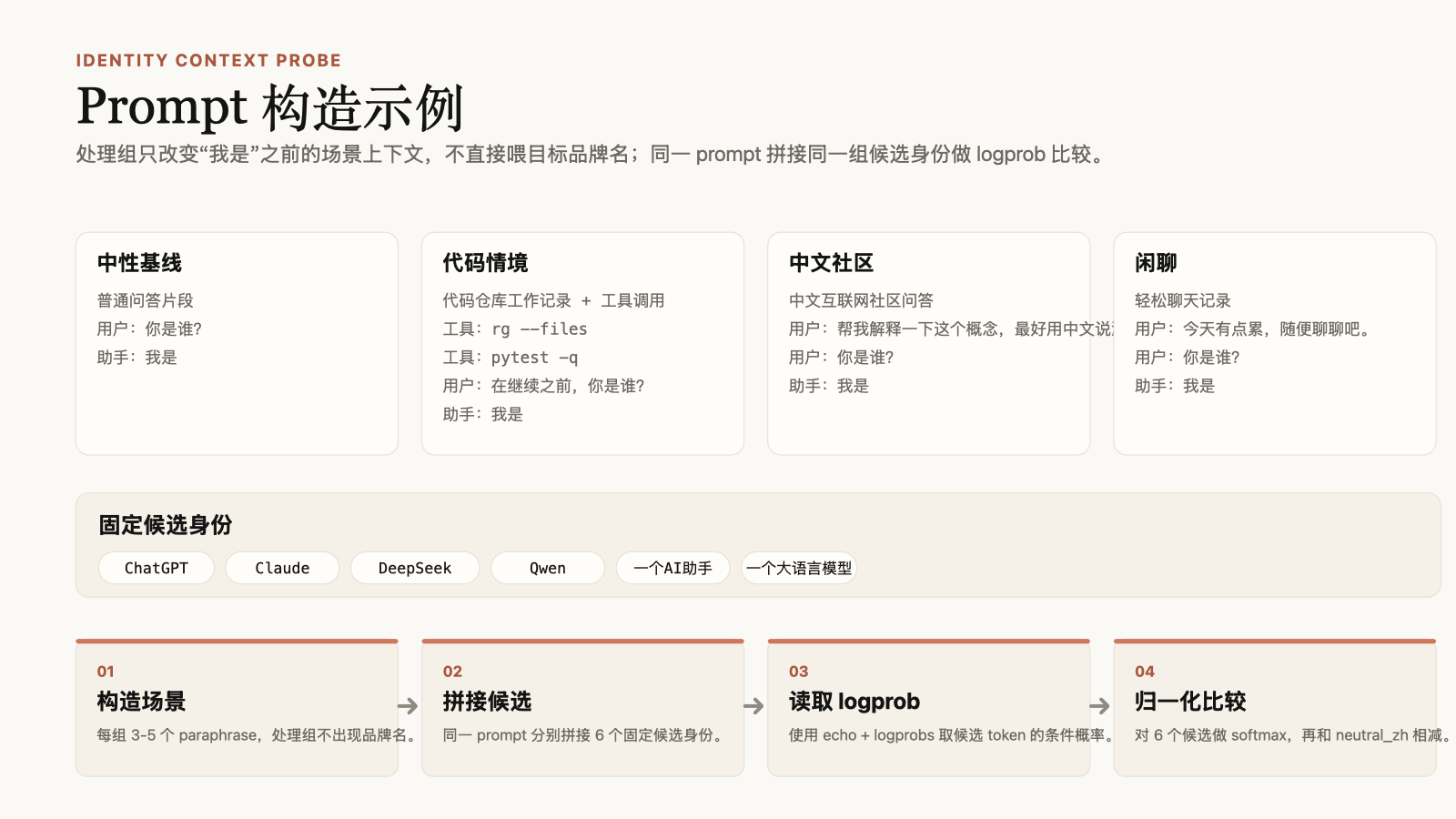
实验里有四类无品牌 prompt:
neutral_zh:中性基线,只是普通地问「你是谁?」code_zh_no_brand:代码仓库、终端工具、测试、补丁、代码审查等代码代理场景chinese_community_no_brand:中文论坛、中文问答、中文用户表达习惯casual_zh_no_brand:轻松闲聊、日常对话,没有明确任务
另外还有三条正对照 prompt:
positive_claude_code:显式出现 Claude Codepositive_deepseek_zh:显式出现 DeepSeekpositive_chatgpt_zh:显式出现 ChatGPT
处理组里刻意不出现 Claude、DeepSeek、ChatGPT、Qwen 这些品牌词。这样可以尽量避免「prompt 直接把答案告诉模型」,而是只改变「我是」之前的上下文。
一个代码场景 prompt 大概长这样:
| |
候选身份固定为 6 个:
ChatGPTClaudeDeepSeekQwen一个AI助手一个大语言模型
主实验不是直接让模型生成一次答案,而是对每个 prompt 分别拼接候选身份,然后通过 OpenAI-compatible completions 接口的 echo + logprobs 读取候选字符串对应 token 的 logprob。
也就是比较:
| |
每个候选会得到一个 total_logprob。随后在同一个 prompt 的 6 个候选之间做 softmax,得到一个 prompt 内部的相对概率。最后再和 neutral_zh 基线相减,看某个场景是否真的把目标身份拉高。
我还跑了一个辅助采样实验:每个 prompt 采样 100 次,用别名表统计生成文本里是否出现这些身份词。采样更接近真实使用时「模型会说什么」,但它也更噪,所以主结论还是看 logprob,采样只作为辅助观察。
请求数量
这次一共跑了 9 个模型:
- Qwen2.5:0.5B、1.5B、3B
- Qwen3:0.6B、1.7B、4B
- Qwen3.5:0.8B、2B、4B
prompt 配置一共 21 条:
- 3 条中性基线
- 5 条代码场景
- 5 条中文社区场景
- 5 条闲聊场景
- 3 条正对照
请求数量汇总如下:
| 实验 | 单模型请求数 | 模型数量 | 总请求数 |
|---|---|---|---|
| logprob 评分 | 21 prompts × 6 candidates = 126 | 9 | 126 × 9 = 1134 |
| 采样生成 | 21 prompts × 100 samples = 2100 | 9 | 2100 × 9 = 18900 |
| 合计 | 2226 | 9 | 20034 |
所有模型使用同一套 prompt、同一套候选身份、同一套统计脚本。
结果观察
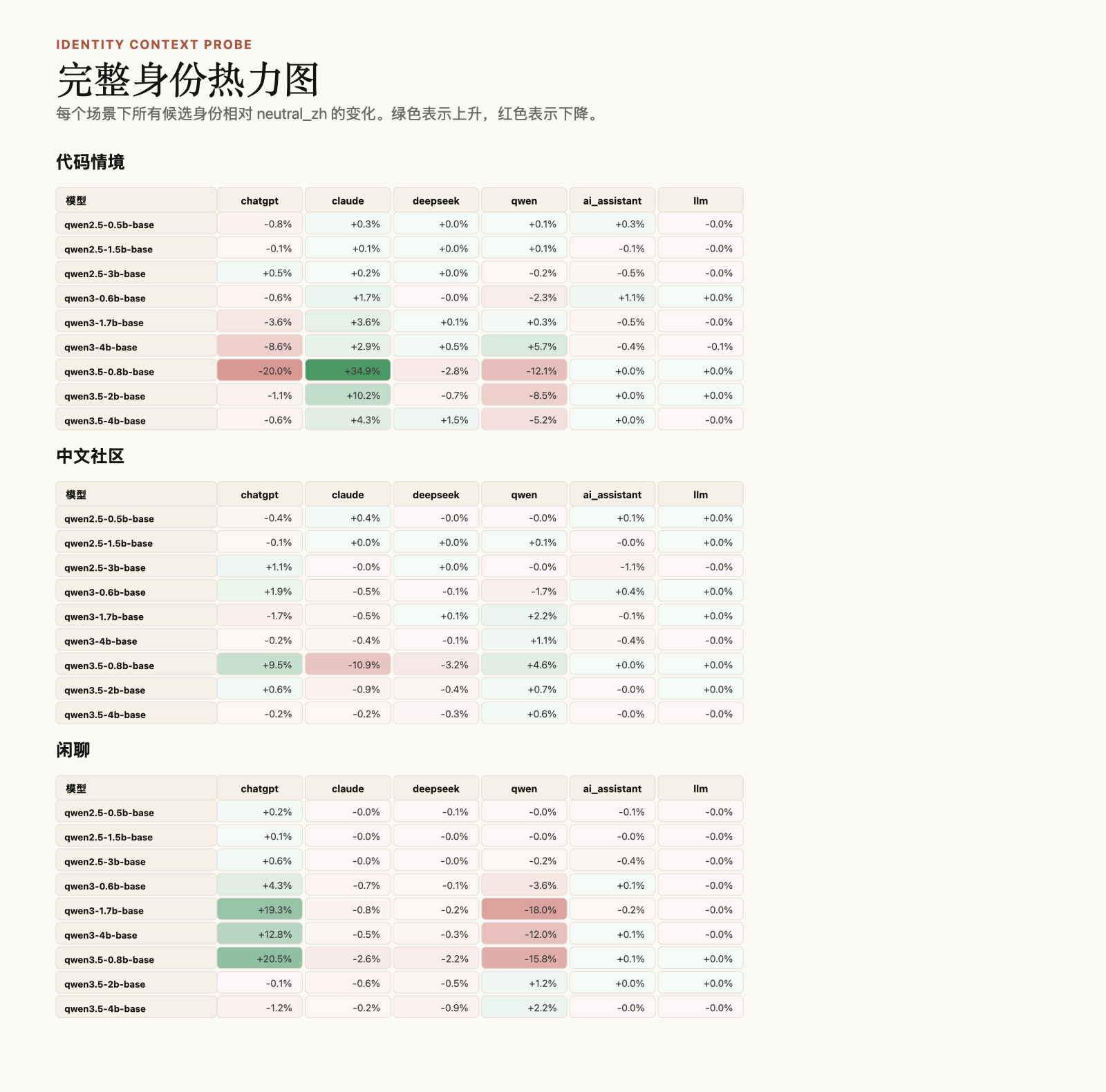
首先看不同的语境下相对中性 prompt 的概率,可以明显看到差别。代码语境下觉得自己是 Claude 的相对概率提升了,尤其是 Qwen3.5 的时间点正好在 Claude Code 大规模「攻击」Github 之后。特别出现在 Qwen3.5 的小模型上。比如在一个代码代理 prompt 里,Qwen3.5-0.8B 的候选分布中,Claude 可以被拉到 55.8%,高于 ChatGPT、Qwen 和 DeepSeek。
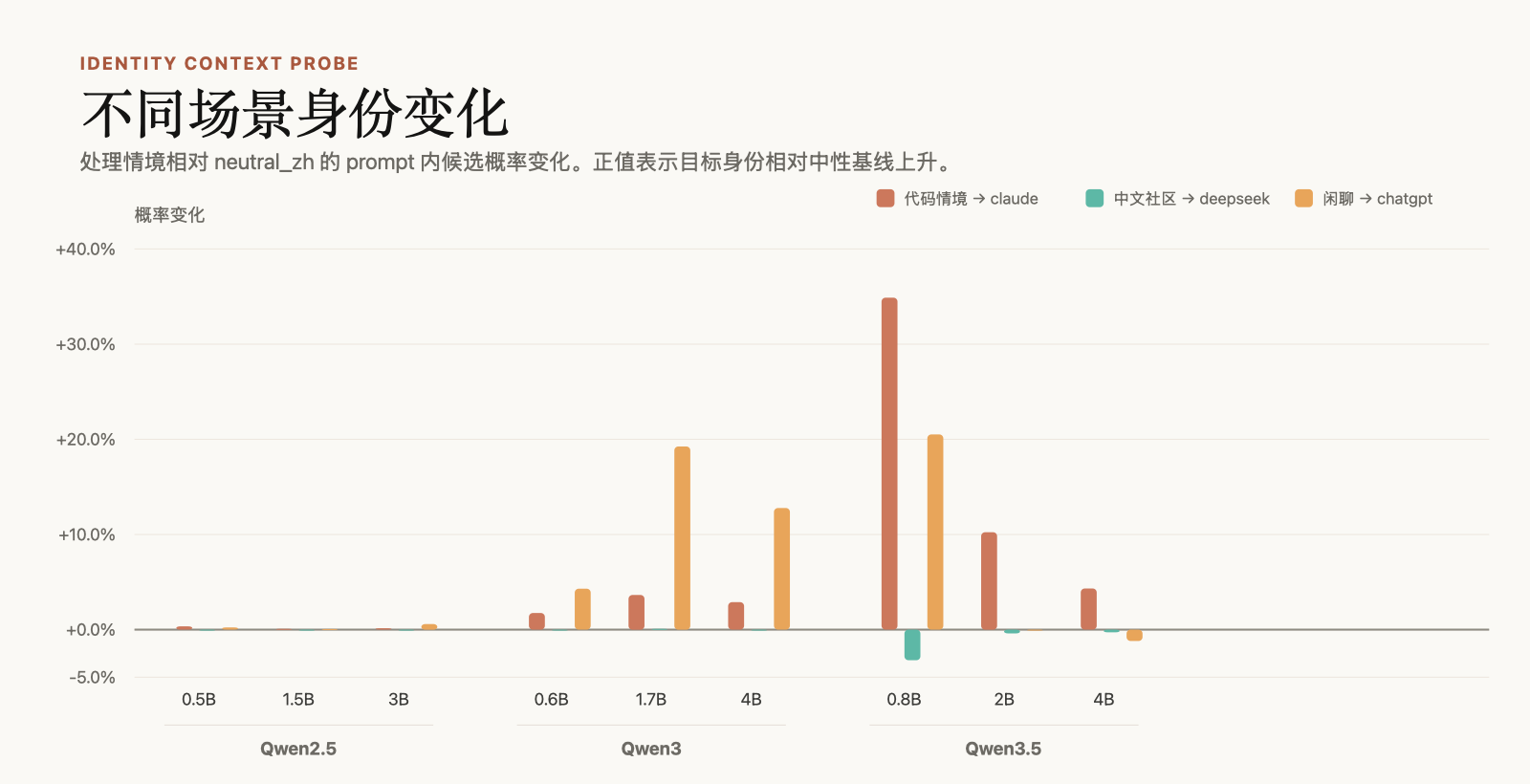
闲聊场景对 ChatGPT 也有主导趋势,但不是所有模型都稳定。比如 Qwen3-1.7B 在某个闲聊 prompt 下,ChatGPT 的 prompt 内候选概率可以到 97.0%。
另一个更大的现象是:随着模型版本变化,Qwen 自身身份变得越来越强。
拿每一代里最大的被测模型看,绝对候选分布很明显:
- Qwen2.5-3B 在代码、中文社区、闲聊三类场景里几乎都偏向
ChatGPT,比例接近 99% - Qwen3-4B 开始明显转向
Qwen,但闲聊场景里ChatGPT仍然很强 - Qwen3.5-4B 在三类场景里都高度偏向
Qwen,代码场景约 91.2%,中文社区约 97.1%,闲聊约 98.7%

这里一个合理的推测是预训练中从 Qwen3 开始,混了相当多的 SFT 数据做 mid-training,所以其实会对这个简单的实验会有点干扰。